听一听创业和满足融资需求的故事。
欢迎致电【镁客·请讲】

Agent57为我们构建更强大的人工智能决策模型奠定了基础。
规划与写作:吴潘
人工智能能比普通人玩得更好吗?心灵深处给出了肯定的回答。最近,DeepMind宣布它们的智能体Agent57首次在所有57款雅达利游戏上超越人类玩家。
近年来,DeepMind一直在研究如何在游戏环境中提高智能体的智能。通常,环境代理在游戏中能够处理的越复杂,它们在真实环境中的适应性就越强。
由代理57挑战的街机学习环境(ALE)包括57个游戏,这为代理的强化学习提供了复杂的挑战。
选择雅达利游戏作为训练数据集的原因是DeepMind表示雅达利游戏足够多样化,可以评估智能体的泛化性能,其次它可以模拟在真实环境中可能遇到的情况,并且雅达利游戏是由独立的组织构建,可以避免实验偏见。
据报道,在Agent57在多台计算机上并行执行,并启用强化学习算法(Reinforcement learning,简称“RL”)驱动智能体采取行动,使得奖励的效果最大化。之前,强化学习在游戏领域取得了很大的进步。例如,OpenAI的OpenAI五号和DeepMind的AlphaStar RL代理分别击败了99.4%的Dota 2玩家和99.8%的Star2玩家。
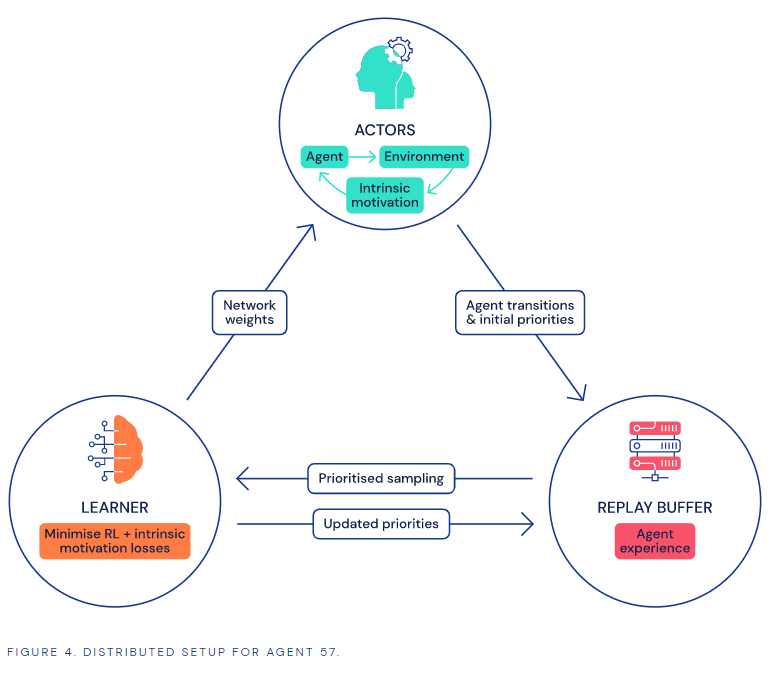
图|代理57的框架
蒙特祖玛,复仇和雅达利的陷阱都很难。人工智能必须尝试各种不同的策略才能找到可行的方法。在Solaris和滑雪游戏中,显示决策结果需要一些时间,这意味着人工智能必须在很长时间内收集尽可能多的信息。
代理57通过让不同的计算机研究游戏的各个方面克服了这些困难,然后将收集到的信息反馈给一个控制器,由控制器对所有这些因素进行分析以制定出最佳策略。
DeepMind将代理57与最先进的算法MuZero、R2D2和NGU进行了比较,代理57显示出更高的平均性能(100)。
研究小组说,“这并不意味着雅达利游戏研究的结束。我们不仅需要关注数据效率,还需要关注整体性能。例如,未来的主要改进可能会是Agent57在探索、规划和信度分配上。”可以降低人工智能操作的计算能力,并在一些更简单的游戏中变得更好。
在雅达利游戏中,Agent57取得了比人类玩家更好的结果,这为我们构建更强大的人工智能决策模型奠定了基础:人工智能不仅能自动完成重复性任务,还能自动推断环境。
星标我们,不要错过
镁客户网络
科学技术|人文|工业