12月19至21日,由中国图象图形学学会(CSIG)、中国人工智能学会(CAAI)、中国计算机学会(CCF)和中国自动化学会(CAA)联合主办的第四届中国模式识别与计算机视觉大会(PRCV2021)在珠海正式召开。作为国内顶级的模式识别和计算机视觉领域的学术盛会,PRCV2021汇聚了国内外从事相关领域研究的广大科研工作者及业界同行,共同分享最新理论和技术成果,提供精彩的学术盛宴。
作为腾讯旗下顶级人工智能实验室,聚焦计算机视觉的腾讯优图实验室也参与了本次大会,腾讯优图实验室高级研究员任玉强在会上作了主题为《腾讯优图近期内容理解领域的研究与应用》的演讲,向参会者分享了腾讯优图在计算机视觉领域中的研究成果和应用实践。

弱监督目标检测与定位
一直以来,全监督目标检测由于出色的效果一直广泛应用于内容理解的各个任务中,但是标注成本一直很高,有统计显示如果按照弱监督要求只标注image-level的类别标签不标注bbox,标注速度可以提高数倍。为了提高效率降低成本,腾讯优图在弱监督目标检测和定位上进行了深入研究。
弱监督检测主要是指训练数据只标注类别标签不标注具体位置框,模型通过训练预测出目标的位置。自2014年MIT提出类别响应图CAM以来,大多数的弱监督目标检测方法主要基于Global Average Pooling (GAP)+Softmax分类网络的输出响应,从空间正则约束方面着手,配合阈值生成检测框。但是这种方法存在2点缺陷:一是无限制的类别响应特征图往往出现局部极高响应现象。二是结构信息丢失,GAP结构将前景目标与背景区域混为一谈,限制了模型定位前景目标的能力。

对此,腾讯优图将研究重点放在如何在隐层的网络中发现更多的目标结构信息,及怎样在网络训练不断加深的情况下加强结构信息保持。首先设计了受限激活模块缓解模型的结构信息弥失的问题,在训练阶段通过计算每个特征位置在类别响应图上的方差分布得到粗略的伪Mask,用以区分前背景;然后利用Sigmoid操作对类别响应特征图进行归一化,最后利用提出的受限激活损失函数LRA引导模型关注目标前景区域。
在推理阶段,腾讯优图首先提出了高阶相似性的定义,用以提取更加完整的目标区域。自相关图生成模块,将CAM的定位结果当做种子节点,分别提取前景与背景的相似性图,通过聚合前背景相似性图得到更精细完整的定位结果。目前腾讯优图所采用的解决方案在两个比较权威的弱监督检测数据集上都取得了比较好的结果,响应图的结构信息更加完整、定位更加准确。
多标签识别
多标签识别中的一个重要问题就是标签之间的共现依赖,为了解决这一问题,之前的工作很多采用了RNN或者GCN的网络结构来处理这种相互关系,但对于标签共现依赖很相近的标签很多研究都没有考虑。
因此腾讯优图提出:除共现依赖以外,空间依赖也是影响多标签预测的重要因素,“滑雪板”和“滑板”在颜色纹理上比较接近,在共现依赖中也都与人的相关性很高,因此只关注共现依赖的方法无法很好的解决这种问题,而“滑雪板”和“滑板”的一个重要区别在于其周围空间是什么,如果周围是雪地,那大概率是“滑雪板”,如果周围是街道,那大概率是“滑板”,因此本文在考虑共现依赖的基础上,又引入对上下文空间依赖的建模,利用joint relation进一步提升多标签识别的准确性。
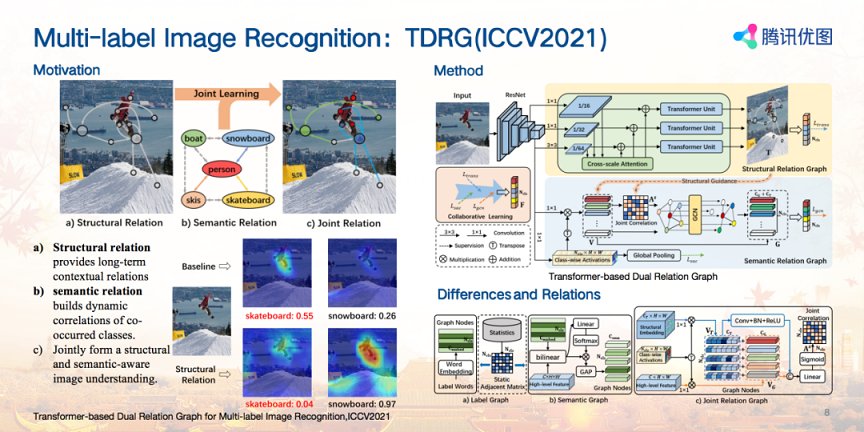
针对以上讨论的motivation,腾讯优图提出一种基于Transformer的双路互补关系学习框架来联合学习空间依赖与共现依赖。针对空间依赖,使用跨尺度Transformer建模长距离空间上下文关联。针对共现依赖,提出类别感知约束和空间关联引导,基于图神经网络联合建模动态语义关联,最后联合这两种互补关系进行协同学习得到鲁棒的多标签预测结果。
细粒度识别
细粒度图像解析是计算机视觉研究的前沿和热点问题,其旨在将高度近似的同类物体区分为不同的子类。现有的细粒度识别算法,比如Bilinear pooling、Trilinear attention,通常使用通道间的高阶特征获取可区分性的细粒度表征,忽略了空间位置关系和不同语义特征间的相互关联,在复杂背景或类间距较小情况下误判较显著。
腾讯优图针对这一问题,创新性地提出了一种特征高阶关系建模的方法,通过挖掘特征间的空间与语义关联来建模高阶关系,合并其中的相似关系得到区分度高的特征。
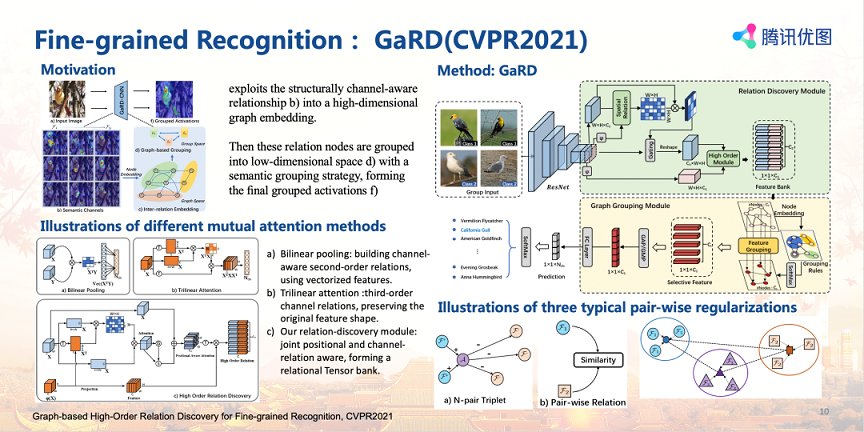
相较于现有的解决方法,腾讯优图提出的方法有三个创新点:首先在relation-discovery module,通过构建异质的跨层网络交互,利用混合高阶特征引入内在的空域关联,构建高维feature bank。其次,为了克服维度灾难同时保留其可区分性,提出了基于图相似度约束的分组算法,利用两个不同的图约束模块,根据语义信息进行分组,最大化其内在似然度,将其约束为少量可区分性组织。
最后,在训练策略上提出了一种平衡分组策略,将不同样本按照中心化采样,进行分组约束迭代,使图像特征倾向于聚类原型,抑制异常样本的表征。该方法在四个国际基准数据集CUB-200-2011, Stanford-Cars, FGVC-Aircrafts, NA-Birds 均达到了领先水平。
弱监督图像描述与定位
弱监督Grounded Image Captioning近年来逐渐受到越来越多的关注。该任务是指对给定的图像自动生成一句话描述图像的内容,同时预测出其中名词对应的目标位置。由于缺乏名词与对应目标的监督信息,该项任务具有很大的难度。
已有的工作主要通过正则化技术依靠注意力机制在生成图像描述的同时预测名词对应的目标的位置。注意力机制的大部分预测结果往往集中于目标的最具判别性的局部位置,无法完整的预测目标的整体内容,导致定位过大、过小或者定位偏移的问题,其中定位过小和定位偏移的错误占绝大部分。
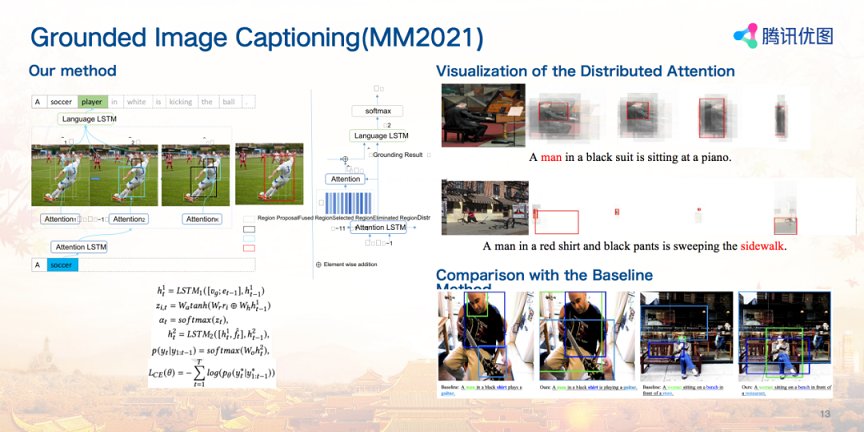
针对以上问题,腾讯优图采用分布式注意力机制的新方法,首先,通过挖掘多个具有相同语义的候选框进行聚合得到最终的比较完整的目标框,来解决局部定位的问题。其次利用多个注意力机制聚合得到的候选框,同时可以降低前面所说的另外2种定位过大和偏移的情况,通过多个注意力机制同时互相校正,显著降低定位错误的case。
视觉AI在业务场景中的应用示例
在内容理解领域中,由于 ACG 场景风格与通用场景之间的差异较大,导致通用模型在动画、漫画领域中的识别能力相对较弱,容易出现大量的漏过和误判。为解决此类问题,腾讯优图提出渐进式领域自适应方法,首先统计源域和目标域的特征分布,用 MMD 缩短通用特征与 ACG 特征分布间的距离,然后提出动态渐进式学习策略 PAS,由易到难进行学习,降低迁移难度。最后通过半监督学习快速迭代面向 ACG 场景的专用模型,极大程度上提升了该场景的识别效果。
在当前网络上的各类违规广告中,低俗、诱导点击广告是打击的重点,其危害性大,隐秘性深。通过分析,目前网络上存在的广告内容为逃避纯文本模型的审核,较少以单模态纯文本的形式出现,而是双模态图像+水印文本,甚至文本做了对抗处理。针对这些强对抗性的违规广告,腾讯优图针对数据特点结合自监督预训练技术,研发出一套多模态广告识别模型,通过采用多模态融合+OCR优化两个手段来缓解因单一模态的信息量不足且存在对抗性导致漏召回的问题。为了提高多模态识别效果,腾讯优图构建了百万级别的文本图像对,采用无标注的自监督预训练方式,进行跨模型预训练,有效提升了基于Transformer特征融合的多模态效果。
互联网内容创作越来越繁荣,劣质甚至违规内容也越来越多。炫富、恶搞营销、暴力恐怖等不良现象受到各大内容平台越来越多的重视,传统内容理解解决方案只能做到检测出敏感元素,至于元素是否恶意违规需要人工审核,效率很低。比如,对于平台来说教材书本上的人民币属于正常情感倾向,人民币炫富属于恶意倾向,传统目标检测算法只能检测出图片中是否含有人民币,无法区分正常倾向还是恶意倾向。同时,图片情感丰富多变,同种元素表达出的情感程度也各不相同。
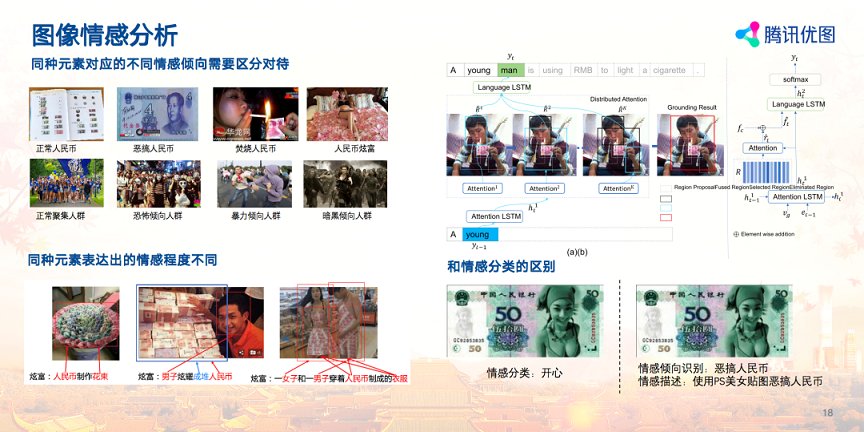
因此可以发现传统离散的情感分类算法很难准确的表达所有情感倾向,于是,腾讯优图基于image caption技术研发了能实现更详细的图像情感分析的系统,在进行情感倾向识别的同时还会输出caption结果用以描述更详细的图像情感状态。这一技术可以更好的帮助内容平台实现更丰富的图像内容理解。